Amazon S3はAmazon Web Servicesによって提供されるクラウドストレージ。容量や通信量に応じて課金される重量課金制のウェブサービス。そこそこの容量でも通信量が多くなければ低価格で利用できるためバックアップ用途にとても相性が良い。
これまでVPSをバックアップ用途に利用していたが、Amazon S3でも簡単にバックアップの仕組みが構築できたので、これからWebサイト等のバックアップを行いたいと考えている方にAmazon S3へバックアップする方法をご紹介したい。
AWS(Amazon Web Services)に登録する
Amazon S3を利用するには、まずAWSにアカウント登録する必要がある。登録画面が英語で迷ってしまったが、本記事を書く際、オフィシャルにわかりやすく登録手順がまとめてあるのを見つけてしまった。まだ登録されていない方は下記を参考に登録されると良いだろう。
バケットの作成
Amazon S3は一般的なレンタルサーバーと違い、FTPでファイルやディレクトリをアップロードするのではなく、専用のコマンドで「バケット」と呼ばれる場所にファイルやディレクトリをアップロードし「オブジェクト」として保存する。バケットはAWSの管理画面から作成する。
AWS管理画面で「アカウント/コンソール > AWS Management Console」と進むとサービスの一覧が表示されるので「S3」をクリックする。
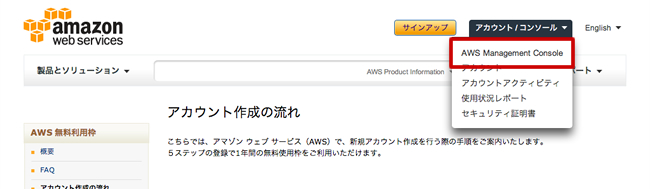
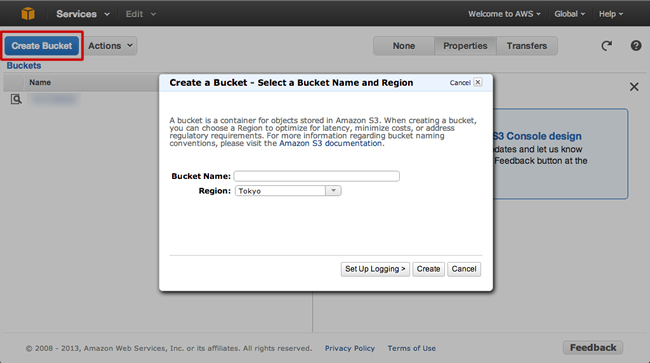
S3の管理画面が開くので、ここで「Create Backet」をクリックし任意のバケット名を入力、リージョン(どこのサーバーを使うか)を選択してバケットを作成する。
アクセスキーの取得
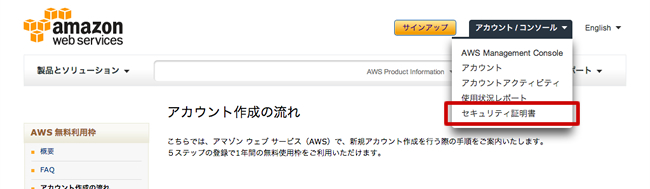
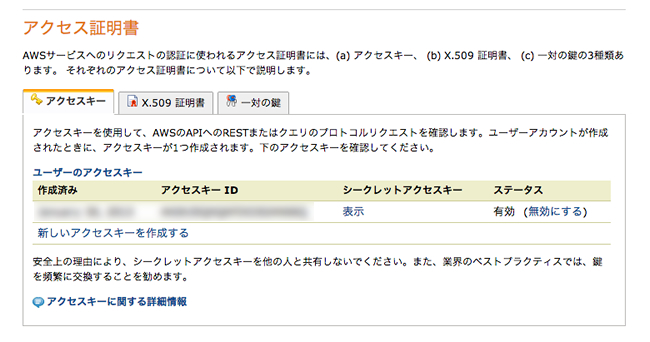
Amazon S3の操作には独自のコマンドを使用する。その際、正しい利用者かの識別のために「アクセスキー」が必要となる。AWS管理画面で「アカウント/コンソール > セキュリティ証明書」と進み、アクセスキーを取得する。
アクセスキーを作成すると「アクセスキーID」と「シークレットアクセスキー」が表示されるので控えておこう。
s3syncのインストール
Amazon S3でデータの転送や同期を行うには、s3syncというrsyncのようなコマンドを使用する。s3syncを使うにはrubyが必要なので、rubyのインストールも行う。
# rubyのインストール $ sudo yum install ruby # s3syncをダウンロード・解凍 $ wget http://s3.amazonaws.com/ServEdge_pub/s3sync/s3sync.tar.gz $ tar zvfx s3sync.tar.gz # configファイルを作成 # s3config.ymlの場所は、環境変数・$S3CONF/・$HOME/.s3conf/・/etc/s3conf/ のいずれか $ sudo mkdir /etc/s3conf/ $ sudo cp s3sync/s3config.yml.example /etc/s3conf/s3config.yml $ sudo vi /etc/s3conf/s3config.yml ############################## aws_access_key_id: xxxxx # アクセスキーIDを記述 aws_secret_access_key: xxxxx # シークレットアクセスキーを記述 S3SYNC_NATIVE_CHARSET: UTF-8 AWS_CALLING_FORMAT: SUBDOMAIN # リージョンが米国以外の場合は必要 ##############################
s3cmdのインストール
s3cmdはAmazon S3を操作するためのコマンド群。今回はs3syncでバックアップデータのアップロードを行うが、容量が増大するのを防ぐために古いアップロードデータをs3cmdで削除することにする。
s3cmdはyumでもインストールできるし、公開されているzipファイルを解凍してそのまま利用することもできる。簡単なyumでのインストールがオススメだが、レンタルサーバーなどyumが使えない環境ではzipファイルをダウンロードしてインストールすることになる。ここではレンタルサーバーの例として「さくらのレンタルサーバー」の場合の設定を記しておく。
# yumでインストールの場合 $ cd /etc/yum.repos.d/ $ wget http://s3tools.org/repo/RHEL_6/s3tools.repo $ sed -i -e s/enabled=1/enabled=0/ s3tools.repo $ yum install s3cmd --enablerepo=s3tools # zipファイルをダウンロードしてインストールの場合(pythonが必要) $ mkdir -p $HOME/local/python $ wget http://peak.telecommunity.com/dist/virtual-python.py $ python virtual-python.py --prefix=$HOME/local/python -v $ vi .cshrc ############################## # 以下を追記 set path = ($HOME/local/python/bin $path) set PYTHONPATH =($HOME/local/python) ############################## # .cshrc再読み込みのため、一旦ログアウトしてログイン $ wget http://peak.telecommunity.com/dist/ez_setup.py $ python ez_setup.py $ wget http://downloads.sourceforge.net/project/s3tools/s3cmd/1.1.0-beta3/s3cmd-1.1.0-beta3.zip $ unzip s3cmd-1.1.0-beta3.zip $ cd s3cmd-1.1.0-beta3 $ python setup.py install # s3cmdの設定(「Access Key」でアクセスキーIDを指定、「Secret Key」でシークレットアクセスキーを指定) $ s3cmd --configure
バックアップを実行するシェルスクリプト
Amazon S3にバックアップを行うために、次の内容でシェルファイルを作成し実行する。下記の例ではAmazon S3に3日分のバックアップデータを保存し、ローカルにはバックアップデータは残さないようにしている。
$ vi backup.sh
###########################
#!/bin/sh
# 何日分保存するか
period=3
# ローカルのバックアップ保存ディレクトリ
backupdir=/usr/local/backup
# バックアップの名前
today=`date '+%Y%m%d'`
# webディレクトリ
webdir=/var/www
# MySQLホスト名
dbhost=localhost
# MySQLユーザ名
dbuser=hoge
# MySQLパスワード
dbpasswd=xxxxx
# Amazon S3バケット名
backet=example
# Amazon S3バックアップ保存ディレクトリ
s3backupdir=backup
# ローカルにバックアップデータを保存
mkdir $backupdir/$today
tar cvfz $backupdir/$today/www.tar.gz $webdir
# mysqlデータを保存
/usr/local/bin/mysqldump -A -h$dbhost -u$dbuser -p$dbpasswd --opt --default-character-set=binary | gzip > $backupdir/$today/mysql.sql.gz
# Amazon S3に転送
# /usr/local/bin/ruby /home/アカウント名/s3sync/s3sync.rb(さくらのレンタルサーバーの場合)
ruby /usr/local/s3sync/s3sync.rb -r --delete $backupdir/$today $backet:$s3backupdir
# ローカルのバックアップデータを削除
rm -rf $backupdir/*
# Amazon S3から古いファイルを削除
# yesterday=`date -v-${period}d +%Y%m%d`(さくらのレンタルサーバーの場合)
yesterday=`date -d "$period days ago" '+%Y%m%d'`
# /home/アカウント名/local/python/bin/s3cmd(さくらのレンタルサーバーの場合)
/usr/bin/s3cmd del -r s3://$backet/$s3backupdir/$yesterday/
/usr/bin/s3cmd del -r s3://$backet/$s3backupdir/$yesterday
###########################
$ chmod 700 backup.sh
